
edgeOps: Benchmarking ML Inference at Edge
1. Introduction
In this blog, we discuss the problem of capturing system statistics when running machine learning (ML) models on resource-constrained edge devices (aka: small platforms with tiny brains - don’t take it literally!). Ready? Let’s dive into the problem (and potential solution).
Imagine an ML practitioner named Zeki, who loves experimenting with training ML models and deploying them on small and resource-constrained edge devices (e.g., Raspberry Pi). One day, Zeki deploys an ML model that unexpectedly consumes excessive resources, causing the device to freeze and break every running operation. In a personal setting, he can afford to power off the device and stop the model manually. But what if Zeki is working in a production system? Can he really afford the downtime caused by restarting a production device?
It depends on the organization and the scenario, of course, but the consequences become much more serious if the system is deployed in a critical environment, such as one related to national security.
This is where edgeOps comes into play. With edgeOps, we capture the average system statistics of the hosting edge device while running inference operations of an ML model with a testing dataset.
2. Overview of the Architecture
edgeOps consists of two main components:
2.1. ML Inference
This component is responsible for running a trained ML model using the provided test dataset. It varies from model to model, and the user can optimize it according to the trained model they are using. For example, a model trained for image processing might require input images of a certain size. This will require users to preprocess the test images to match that size so that the trained model can process them as designed. Similarly, a model trained for sensor data (e.g., acceleration) will require the inference component to be modified accordingly. The model-agnostic design of this inference component allows end users to try different types of ML models with edgeOps.
2.2. Resource Monitoring
This component is mainly responsible for monitoring the resources utilized by the ML model. Currently, edgeOps focuses on memory consumption, CPU utilization, and inference latency. Since each iteration of an inference model can result in different resource utilization due to background services running on the edge device, the resource monitoring component performs multiple iterations of ML inference and provides average statistics of resource consumption.
In addition to these two components, a wrapper component (i.e., edgeOps.sh) is used to connect all components and support statistics collection. As input, edgeOps takes trained ML model(s) and test dataset(s). As output, it generates corresponding CSV and text files containing average resource utilization statistics. The following figure summarizes the overview of the edgeOps architecture.
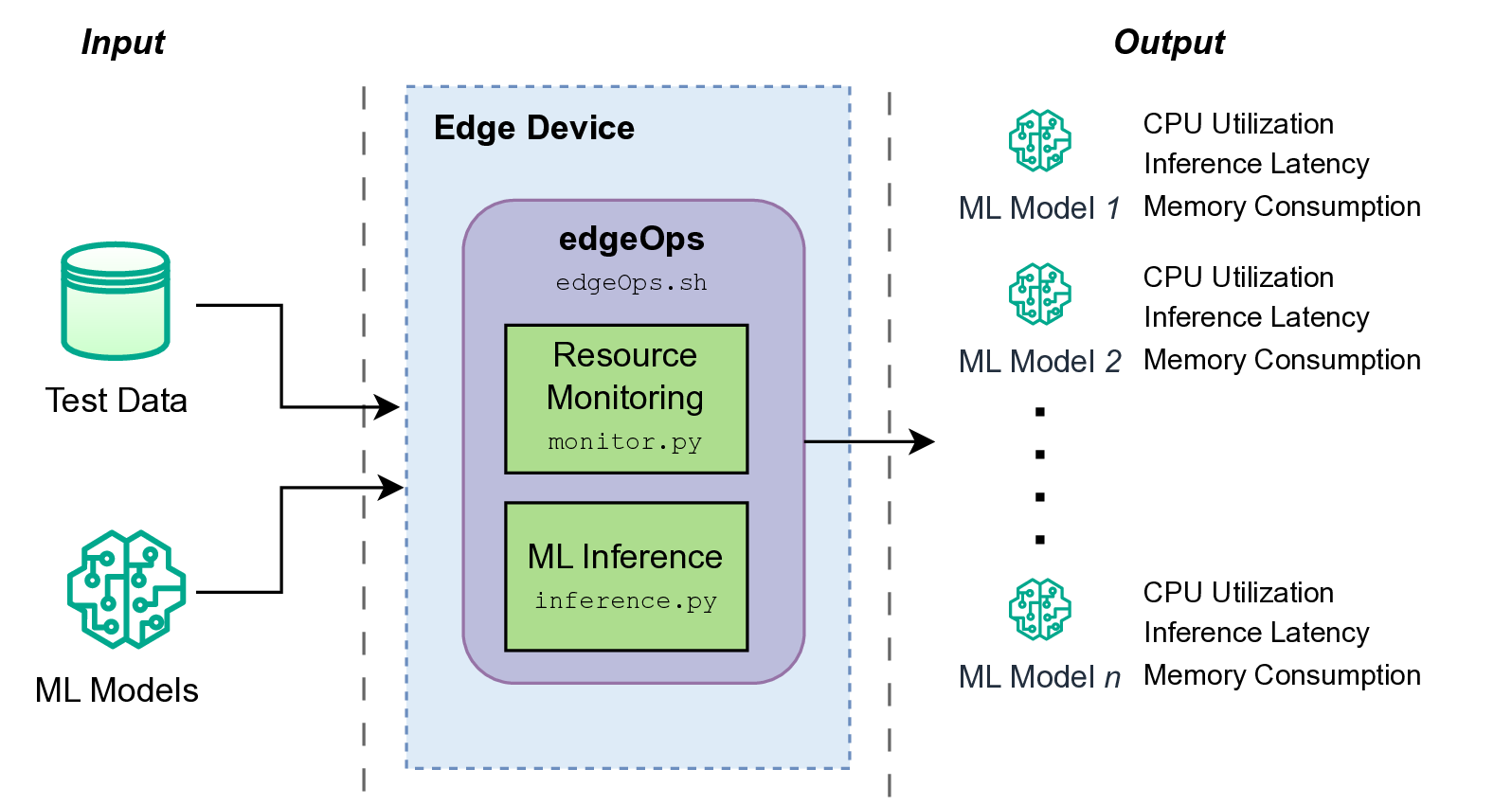
3. Working
For capturing resource utilization, edgeOps uses different approaches designed after accounting for various challenges (details can be found in the paper). For memory consumption, edgeOps relies on the Python memory_profiler library. For inference latency, the built-in date utility of the Linux environment is used with nanosecond precision. Additionally, the psutil library is used to capture CPU utilization.
To ensure isolation of statistics for each iteration of ML inference, edgeOps inserts padded chunks of 30 seconds before and after each iteration. In addition to providing isolation, these padded chunks also help in measuring CPU utilization. Average CPU utilization is measured by subtracting the average CPU usage under ML inference from the average CPU usage during the padded chunks (when the ML inference is not operational). Each iteration of ML inference results in a CSV file. The following figure shows the CPU utilization from one such CSV file. The padded chunks can be observed surrounding the elevated plateau in the graph, where the plateau represents CPU utilization during ML inference.
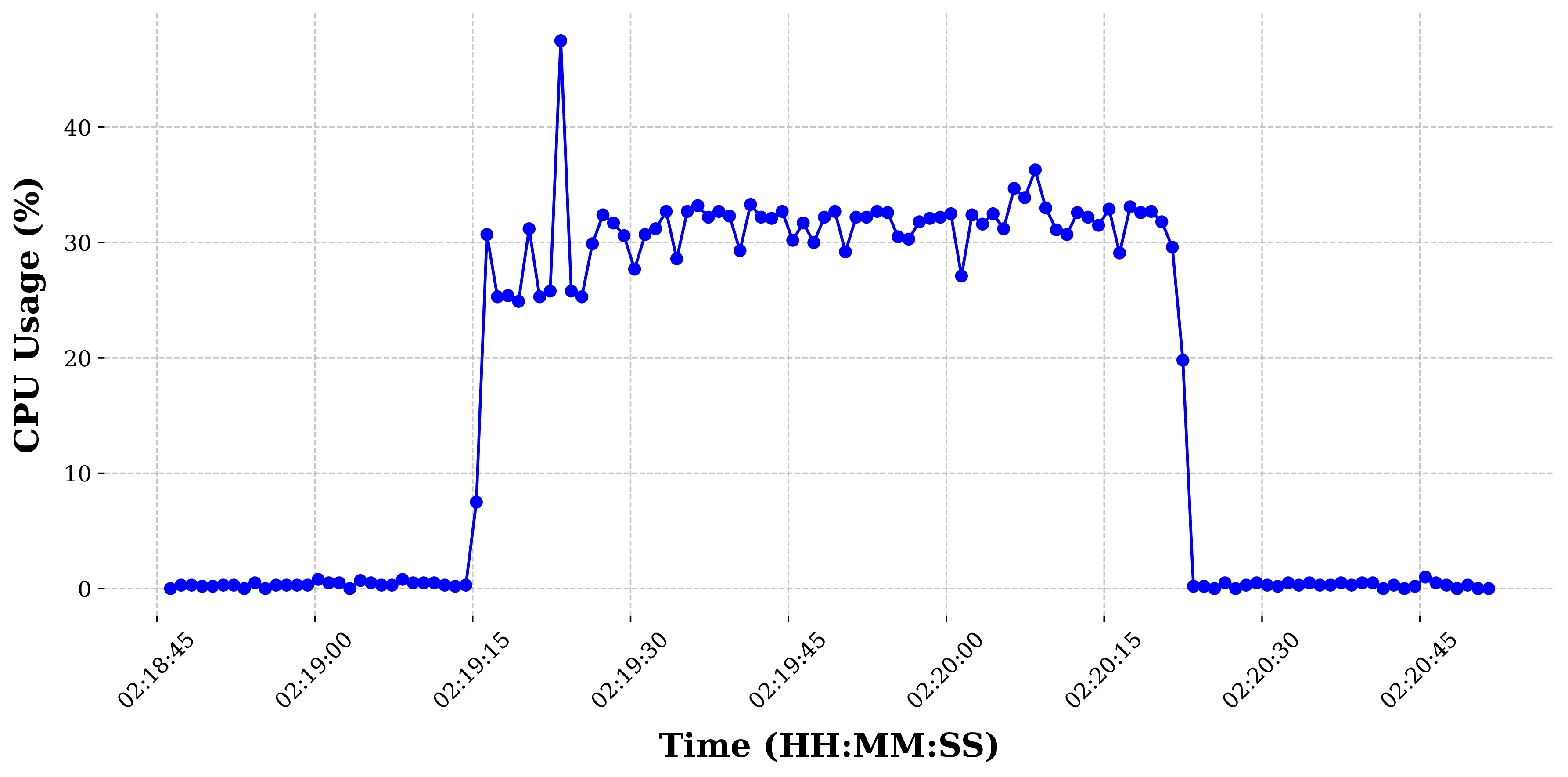
Unlike CPU utilization, memory usage is recorded in a single text file with the average memory usage for each iteration. These output files can be analyzed to extract all three resource utilization metrics (i.e., inference latency, CPU utilization, and memory consumption).
4. Usage
How do we use edgeOps? Well, the answer is quite simple. As discussed earlier, edgeOps consists of two components, and all you need to do is modify the inference component according to your ML model and test dataset. Once the inference component is modified, open a terminal and run the main script (i.e., edgeOps.sh).
$ bash edgeOps.sh
5. Demo with a Trained Model
Clone/download the GitHub repository for edgeOps.
$ git clone https://github.com/smfarjad/edgeOps.git
Unzip (if needed) and navigate to the downloaded repository.
$ cd edgeOps-main
Create an empty directory models.
$ mkdir models
Request the model via sfarjad@unomaha.edu and move the downloaded model in models directory. I will share the access to download the model. However, the model can be viewed at: Google Drive.
Open inference.py, update the path to the trained model in the model variable.
$ model = tf.keras.models.load_model("models/cnn_image_classification_model.h5") # update accordingly
Run edgeOps.sh.
$ bash edgeOps.sh
It will result in one memory profile text file that will be containing memory usage data and ten CSV files moved to a sub directory within the same repository director.
6. Conclusion
This blog provides a very brief overview of edgeOps, a tool for benchmarking machine learning (inference) operations at the edge. The development of edgeOps was motivated by challenges we experienced during another project, which focused on creating a secure edge computing reference architecture for structural health monitoring. edgeOps offers a scalable and easy-to-deploy solution that can be integrated into any edge computing project. However, we do not recommend using it in production systems or security-critical environments at this stage, as it is still in the early phases of development and requires further maturity.
If you’re interested in exploring edgeOps and the reference architecture project in more detail, we recommend checking out our conference paper. If you face any issues or would like to provide feedback, please leave a comment here or connect with me via email.
7. References
Link to GitHub Repository for edgeOps: https://github.com/smfarjad/edgeOps
Citation:
@inproceedings{10.1145/3696673.3723074,
author = {Farjad, Sheikh Muhammad and Patllola, Sandeep Reddy and Kassa, Yonas and Grispos, George and Gandhi, Robin},
title = {Secure Edge Computing Reference Architecture for Data-driven Structural Health Monitoring: Lessons Learned from Implementation and Benchmarking},
year = {2025},
isbn = {9798400712777},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3696673.3723074},
doi = {10.1145/3696673.3723074},
pages = {145–154},
numpages = {10},
keywords = {edge computing, structural health monitoring, machine learning},
location = {Southeast Missouri State University, Cape Girardeau, MO, USA},
series = {ACMSE 2025}
}

Leave a comment